Lab3: User Environments
整个实验部分框架图:

系统调用是通过中断来进行的,syscall()从用户态到内核态的陷入过程:

目录/user和/lib是用户态的程序,/kern和/inc(/inc是内核态的函数库文件,供内核内部调用)是运行在内核中的程序。
Part A: User Environments and Exception Handling
Environment State
JOS中将thread和address space的概念具体化。其中thread具体指的就是保存下来的寄存器的值env_tf,address space是page directory(env_pgdir)。
Allocating the Environments Array
exercise 1
按照之前实验的过程,我们需要为environment分配相应的管理元数据空间,并且对虚拟空间和物理页地址进行映射。根据
/inc/memlayout.h中的分配对权限进行分分配,用户态仅可读。
envs = (struct Env*)boot_alloc(NENV*sizeof(struct Env));
memset(envs, 0, NENV*sizeof(struct Env));
boot_map_region(kern_pgdir, UENVS, PTSIZE, PADDR(envs), PTE_U);
Creating and Running Environments
在之前的实验中,我们已经在boot loader中加载了一个内核二进制的文件,并且运行。
这一部分,我们就是从内核态加载一个二进制文件,在用户态运行。
exercise 2
在
env.c文件中,我们需要完成下面的函数功能:env_init(): 初始化我们在exercise 1中分配的有关environments的元数据,将这些元数据通过
env_free_list连接到一起。调用 env_init_percpu(),初始化一些段寄存器。env_setup_vm(): 建立该environment的页目录管理空间,并且将内核的页目录管理内容复制到这个新创建的地方,将UVPY(Cur. Page Table part)虚拟地址这个部分的物理地址更改为当前物理页面的物理地址。
region_alloc(): 通过elf文件中的memsz和p_va申请若干的物理页,并且进行虚拟地址和物理地址的映射,保存到当前environment的页目录中。
load_icode(): 解析一个ELF文件,将其加载到user environment中,有点类似于加载内核的镜像ELF一样。
env_create(): 使用env_alloc()(从env_free_list中分配一个env 元数据变量)和load_icode()
env_run(): 本实验的一个核心问题,怎么从内核态转换到用户态。
上面若干函数调用过程:
env_init()
env_create()
env_alloc()
- env_setup_vm()
load_icode()
- region_alloc()
env_run()
env_init()部分的实现思路及代码:
将空闲的envs链接起来
int counter;
env_free_list = NULL;
for (counter = NENV - 1; counter >= 0; --counter) {
envs[counter].env_id = 0;
envs[counter].env_status = ENV_FREE;
envs[counter].env_link = env_free_list;
env_free_list = &envs[counter];
}
env_setup_vm():
建立每一个进程的页目录管理。
++p->pp_ref;
e->env_pgdir = (pde_t *)page2kva(p);
memcpy(e->env_pgdir, kern_pgdir, PGSIZE);
// UVPT maps the env's own page table read-only.
// Permissions: kernel R, user R
e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_P | PTE_U;
region_alloc():
分配并且映射物理内存。
static void
region_alloc(struct Env *e, void *va, size_t len)
{
// LAB 3: Your code here.
// (But only if you need it for load_icode.)
//
// Hint: It is easier to use region_alloc if the caller can pass
// 'va' and 'len' values that are not page-aligned.
// You should round va down, and round (va + len) up.
// (Watch out for corner-cases!)
struct PageInfo *page = NULL;
va = ROUNDDOWN(va, PGSIZE);
void *end = (void *)ROUNDUP(va + len, PGSIZE);
for (; va < end; va += PGSIZE) {
if (!(page = page_alloc(ALLOC_ZERO)))
panic("region_alloc: alloc failed.");
if (page_insert(e->env_pgdir, page, va, PTE_U | PTE_W))
panic("region_alloc: page mapping failed.");
}
}
load_icode():
将二进制的程序加载到内存中
struct Elf *elf_header = (struct Elf *)binary;
if (elf_header->e_magic != ELF_MAGIC)
panic("load_icode: illegal ELF format.");
lcr3(PADDR(e->env_pgdir));
struct Proghdr *ph = (struct Proghdr *)((uint8_t *)(elf_header) + elf_header->e_phoff);
struct Proghdr *eph = ph + elf_header->e_phnum;
for (; ph < eph; ++ph) {
if (ph->p_type == ELF_PROG_LOAD) {
region_alloc(e, (void *)ph->p_va, ph->p_memsz);
memmove((void *)ph->p_pa, binary + ph->p_offset, ph->p_filesz);
memset((void *)(ph->p_pa + ph->p_filesz), 0, ph->p_memsz - ph->p_filesz);
}
}
e->env_tf.tf_eip = elf_header->e_entry;
lcr3(PADDR(kern_pgdir));
region_alloc(e, (void *)(USTACKTOP - PGSIZE), PGSIZE);
当上面的功能完成之后,内核会去执行一个hello的ELF文件,但是一旦执行到int指令的程序,就会有问题。
首先在这个节点上还没有任何硬件初始化来处理异常。
当内核发现没有建立异常处理机制时,会产生a double fault exception。
并且最终放弃,给出"triple fault"。
在env_pop_tf()函数中的iret指令后会从内核进入到用户模式,这个一个分界的指令。
说说这个iret的含义:
在一般的函数调用中,我们call address之后一定会有一个ret指令,该指令就是返回call下一条指令地址。
iret指的是中断的返回。我们之前都没有调用哪来的返回啊?
这就是从内核态切换到用户态的精髓所在了。我们在之前的初始化程序中初始化了若干的寄存器,例如:
//env_alloc()
e->env_tf.tf_ds = GD_UD | 3;
e->env_tf.tf_es = GD_UD | 3;
e->env_tf.tf_ss = GD_UD | 3;
e->env_tf.tf_esp = USTACKTOP;
e->env_tf.tf_cs = GD_UT | 3;
我们看到我们初始化了environment的栈设置到了USTACKTOP。
我们首先将esp移动到了tf结构体,然后iret相当于是将栈中的内容赋值到了相应的寄存器中:

我们将相应的结构体和值相对应,发现确实是这样的。
struct Trapframe {
struct PushRegs tf_regs;
uint16_t tf_es;
uint16_t tf_padding1;
uint16_t tf_ds;
uint16_t tf_padding2;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
} __attribute__((packed));
当我们执行完iret后,我们的esp寄存器确实在了USTACKTOP这里:

此刻我们在/lib/entry.S中。
知道了怎么从内核->用户态,那么我们怎么从用户态->内核态呢?
我们知道,我们都是通过中断进入到内核态的,那么在中断之前,我们观察栈:
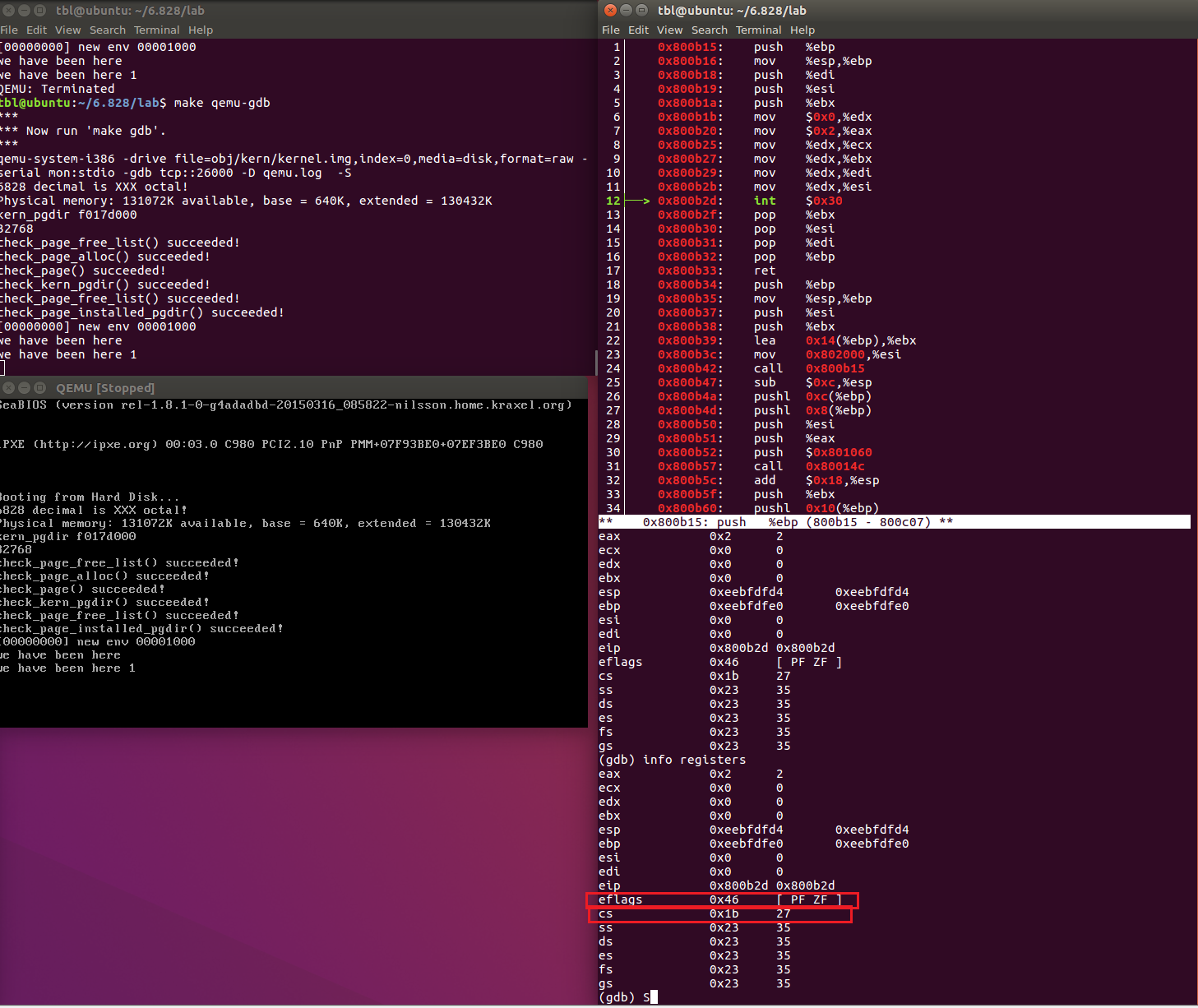
发现此时执行的代码依旧是在用户态(地址为0x800b2d较低)。
我们特意打印了一些寄存器的值,看看int后会将哪些寄存器的值压入。
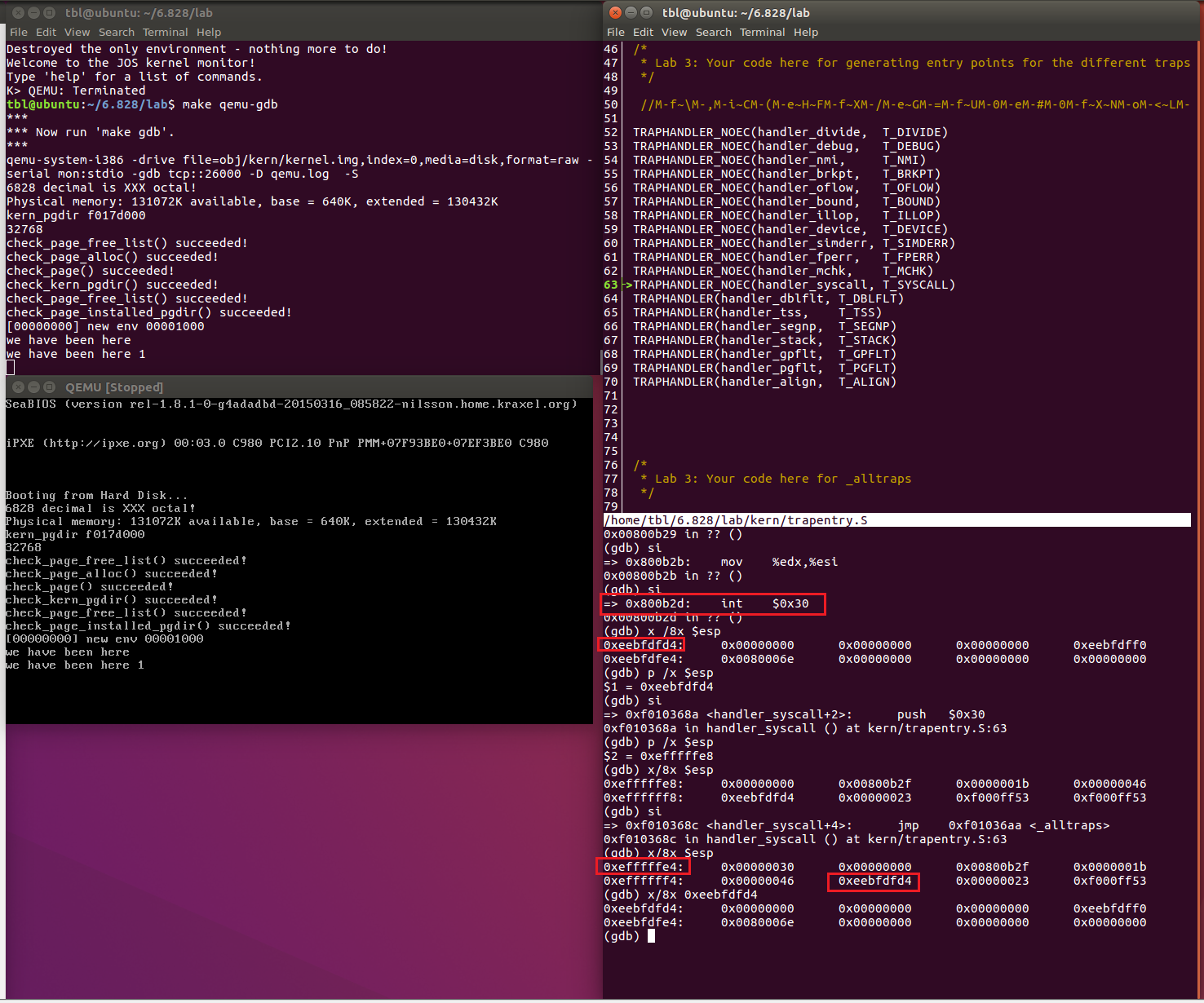
我们发现了下面的压栈顺序:
ss
old esp
eflags
cs
old eip
0(我也不知道是什么寄存器的值,可能是error code)
中断类型
并且此刻的栈值为0xefffffe8,查看memlayout.h发现就是CPU0的内核栈。
并且我们发现这个栈值并不是原来kernel所在stack的值,完全是一个不同的栈(CPU0的栈,内核栈从内核态切换到用户态一去不复返了)。这也是为什么软中断不能嵌套的一个原因,因为从用户态到内核态都是从KSTACKTOP往下改变的(后面我们会知道中断向量表中0-31号中断属于系统中断,应该是可以嵌套的)。
于是,我们终于搞懂了内核->用户态,用户态->内核态的全过程。
之后我们上面做的工作都应该正确直到执行int $30。确保上面工作的正常。
Handling Interrupts and Exceptions
阅读i386手册,去了解中断的原理
本实验中,exception, trap, interrupt, fault 和 abort没有本质的区别。
call和int的区别:
在调用call的过程中,会将call的下一条指令压入到栈中。(栈帧是连续的)
而在int 指令中,首先跳转到新的栈地址(栈帧是不连续的),依次压入原esp,eflags,cs,和int下一条指令地址。
本质上压栈的结构是这样的:
+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20 <---- ESP
+--------------------+
如下面过程所示,将调用前和调用后的栈空间内容显示出来,并且这个内容在前面用户态->内核态的切换已经讲过了,主要就是想强调中断压栈顺序的重要性:
下面的两个机制保证了中断的有序进行:
中断向量表:x86中断向量表最多支持256个中断向量,为什么是怎么大也是系统的规定。主要在表中记录下面的两个值:
EIP:中断发生了应该跳转到哪里
CS 寄存器的值,包括末两位指示优先级的值(JOS中,所有的中断都是在内核模式进行的,因此优先级=0)
The Task State Segment(TSS):系统需要一个地方来存储旧的处理器的状态。在JOS中,我们仅仅使用
ESP0和SS0,这也是为什么我们从用户态->内核态,栈寄存器一下子就变成了KSTACKTOP的原因,是因为TSS在从内核态->用户态的时候就已经保存好了内核的状态,方便能够返回内核态。这个东西主要依靠
tr寄存器的支持,tr寄存器的结构:
因此整个找到原来处理器状态的过程为,其中绿色的框表示系统中涉及到的初始化的部分:

我们初始化了
tr寄存器的SELECTOR部分,从而能够通过GDT来找到TSS,找到TSS中的old ESP和CS就确定了原来栈的状况了,EIP和CS根据中断向量表来确定。
// 初始化部分
// Initialize the TSS slot of the gdt.
gdt[GD_TSS0 >> 3] = SEG16(STS_T32A, (uint32_t) (&ts),
sizeof(struct Taskstate) - 1, 0);
gdt[GD_TSS0 >> 3].sd_s = 0;
ltr(GD_TSS0);
综上,我们想要从用户态转移到内核态进行小心的处理,就需要借助中断向量表和TSS,从中断向量表中加载EIP和CS,从TSS中加载ESP和SS,从而就完成了用户态->内核态的转移工作。
GDT, IDT, LDT和TSS的关系
JOS所有的实验都没有使用LDT(local descriptor table)。它的作用是定位正在运行的处理器(processor)的segment,并且入口保存到了GDT,配合LDTR (Local Descriptor Table Register)一起使用。
GDT在JOS中主要是保存各段的位置等信息,配合若干寄存器使用如SS,TR(task register)等等。
IDT[256]中断向量表
TSS通过tr寄存器和GDT能够找到。
Basics of Protected Control Transfer
Types of Exceptions and Interrupts
有0-31的系统内核内部的中断(the processor exceptions)。
可自由定义的软中断。
硬件中断。
其中第一种是可以嵌套的,其他两种应该不能进行嵌套。
一个中断发生的例子
Trapframe结构在栈中建立的过程,以int $0x30为例:
int指令会从用户栈切换到内核栈KSTACKTOP。并且依次压入以下的值:
(xxx)(目前未知)
ss
old esp
eflags
cs
old eip
error code
/kern/trapentry.S中有下面的指令:pushl $(num);
现在的栈内容为:
<---------------KSTACKTOP
(xxx)(目前未知)
ss
old esp
eflags
cs
old eip
error code
中断类型
_alltraps执行完相应的压栈指令,内存为:
<---------------KSTACKTOP
(xxx)(目前未知)
ss
old esp
eflags
cs
old eip
error code
中断类型
ds
es
若干通用寄存器值
上面就构建了一个完整的Trapframe,为什么呢?我们再次对比Trapframe的结构体变量结构:
struct Trapframe {
struct PushRegs tf_regs;
uint16_t tf_es;
uint16_t tf_padding1;
uint16_t tf_ds;
uint16_t tf_padding2;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
} __attribute__((packed));
栈中存放的就是这个结构体啊。
总结构建按Trapframe的步骤就是:
int $0x30
pushl $(num)
pushl %ds
pushl %es
pushal //压入通用寄存器的值
构造完了Trapframe之后,会调用call trap,trap调用的参数如下:trap(struct Trapframe *tf)。这就进一步的验证了lab1中函数栈的结构问题了,再次放上图,并且在原来的图上增加了Trapframe的位置:

这就是整个trap()调用的机制了。
Nested Exceptions and Interrupts
若在用户态->内核态后,在内核态又发生了新的中断,那么栈是在原来的基础上进行改变的。
因为没有新的栈空间的转变,因此我们在调用中断的时候不需要压入old ss和old esp。
+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20 <---- ESP
+--------------------+
原来的压栈顺序变为了:
+--------------------+ <---- old ESP
| old EFLAGS | " - 4
| 0x00000 | old CS | " - 8
| old EIP | " - 12
+--------------------+
Setting Up the IDT
exercise 4
完成idt的初始化
建立相应的Trapframe
实现的_alltraps 函数应该:
- 将值压入堆栈,使堆栈看起来像一个Trapframe
- 加载GD_KD 进入%ds 以及%es
- 使用pusl %esp 给Trapframe 传递指针,作为trap() 的参数
- 调用trap
通过上面的两个部分,我们就能够通过一些测试:
divzero,softint, andbadsegment
定义相应的处理函数
/*
* Lab 3: Your code here for generating entry points for the different traps.
*/
//本部分是函数声明,并不是顺序执行的部分。
TRAPHANDLER_NOEC(handler_divide, T_DIVIDE)
TRAPHANDLER_NOEC(handler_debug, T_DEBUG)
TRAPHANDLER_NOEC(handler_nmi, T_NMI)
TRAPHANDLER_NOEC(handler_brkpt, T_BRKPT)
TRAPHANDLER_NOEC(handler_oflow, T_OFLOW)
TRAPHANDLER_NOEC(handler_bound, T_BOUND)
TRAPHANDLER_NOEC(handler_illop, T_ILLOP)
TRAPHANDLER_NOEC(handler_device, T_DEVICE)
TRAPHANDLER_NOEC(handler_simderr, T_SIMDERR)
TRAPHANDLER_NOEC(handler_fperr, T_FPERR)
TRAPHANDLER_NOEC(handler_mchk, T_MCHK)
TRAPHANDLER_NOEC(handler_syscall, T_SYSCALL)
TRAPHANDLER(handler_dblflt, T_DBLFLT)
TRAPHANDLER(handler_tss, T_TSS)
TRAPHANDLER(handler_segnp, T_SEGNP)
TRAPHANDLER(handler_stack, T_STACK)
TRAPHANDLER(handler_gpflt, T_GPFLT)
TRAPHANDLER(handler_pgflt, T_PGFLT)
TRAPHANDLER(handler_align, T_ALIGN)
在trap.c 中完成trap_init,对于系统的IDT 表进行初始化:
//这些函数的实现都在trapentry.S中实现。
void handler_divide();
void handler_debug();
void handler_nmi();
void handler_brkpt();
void handler_oflow();
void handler_bound();
void handler_illop();
void handler_device();
void handler_simderr();
void handler_fperr();
void handler_mchk();
void handler_syscall();
void handler_dblflt();
void handler_tss();
void handler_segnp();
void handler_stack();
void handler_gpflt();
void handler_pgflt();
void handler_align();
void
trap_init(void)
{
extern struct Segdesc gdt[];
// LAB 3: Your code here.
SETGATE(idt[T_DIVIDE], 0, GD_KT, handler_divide, 0);
SETGATE(idt[T_DEBUG], 0, GD_KT, handler_debug, 0);
SETGATE(idt[T_NMI], 0, GD_KT, handler_nmi, 0);
SETGATE(idt[T_BRKPT], 0, GD_KT, handler_brkpt, 3);
SETGATE(idt[T_OFLOW], 0, GD_KT, handler_oflow, 0);
SETGATE(idt[T_BOUND], 0, GD_KT, handler_bound, 0);
SETGATE(idt[T_ILLOP], 0, GD_KT, handler_illop, 0);
SETGATE(idt[T_DEVICE], 0, GD_KT, handler_device, 0);
SETGATE(idt[T_SIMDERR], 0, GD_KT, handler_simderr, 0);
SETGATE(idt[T_FPERR], 0, GD_KT, handler_fperr, 0);
SETGATE(idt[T_MCHK], 0, GD_KT, handler_mchk, 0);
SETGATE(idt[T_SYSCALL], 0, GD_KT, handler_syscall, 3);
SETGATE(idt[T_DBLFLT], 0, GD_KT, handler_dblflt, 0);
SETGATE(idt[T_TSS], 0, GD_KT, handler_tss, 0);
SETGATE(idt[T_SEGNP], 0, GD_KT, handler_segnp, 0);
SETGATE(idt[T_STACK], 0, GD_KT, handler_stack, 0);
SETGATE(idt[T_GPFLT], 0, GD_KT, handler_gpflt, 0);
SETGATE(idt[T_PGFLT], 0, GD_KT, handler_pgflt, 0);
SETGATE(idt[T_ALIGN], 0, GD_KT, handler_align, 0);
// Per-CPU setup
trap_init_percpu();
}
Q1: 为什么每一个中断都需要一个单独的中断函数进行处理?而不是放在一个函数中进行处理?
有的函数需要返回,有的不需要,可能处理的级别也是不同的(有在用户态(如syscall),有在内核态)因此分开处理较为的明确。当然没有一定的说法,如果一定要放在一个函数中处理也是可以的。
Q2: 在/user/softint.c中试图产生一个int $14的中断,但是在实际的过程中却产生的是13号中断general protection fault,这是为什么?如果允许用户产生14号中断,那么会发生什么?
首先是在用户态不允许进行越权中断的,因此不论使用什么中断,都会产生13号中断。如果运行调用14号中断,相当于是允许在用户态调用内核态的中断,这很可能破坏内核中的状态。其实在用户态能有限的调用一些中断,从而能够从用户态陷入到内核态,比如handler_syscall和handler_brkpt。
综上,part A主要做的就是创建用户态environment,iret将内存中的值赋值到相应的寄存器中,从而能够从内核态切换到用户态。然后我们又了解了怎么从用户态切换到内核态的过程,栈中值是怎么变化的。并且这个Trapframe是我们之后从内核态返回用户态的关键,至于怎么返回,则和初次从内核态->用户态的方法是一致的。
Part B: Page Faults, Breakpoints Exceptions, and System Calls
在上面的中断的基础之上,我们需要实现更多的系统原语。
Handling Page Faults
// buggy program - faults with a read from location zero
#include <inc/lib.h>
void
umain(int argc, char **argv)
{
cprintf("I read %08x from location 0!\n", *(unsigned*)0);
}
我们看看这个中断是怎么触发的,在cprintf函数调用进行单步调试,得到下面的信息:
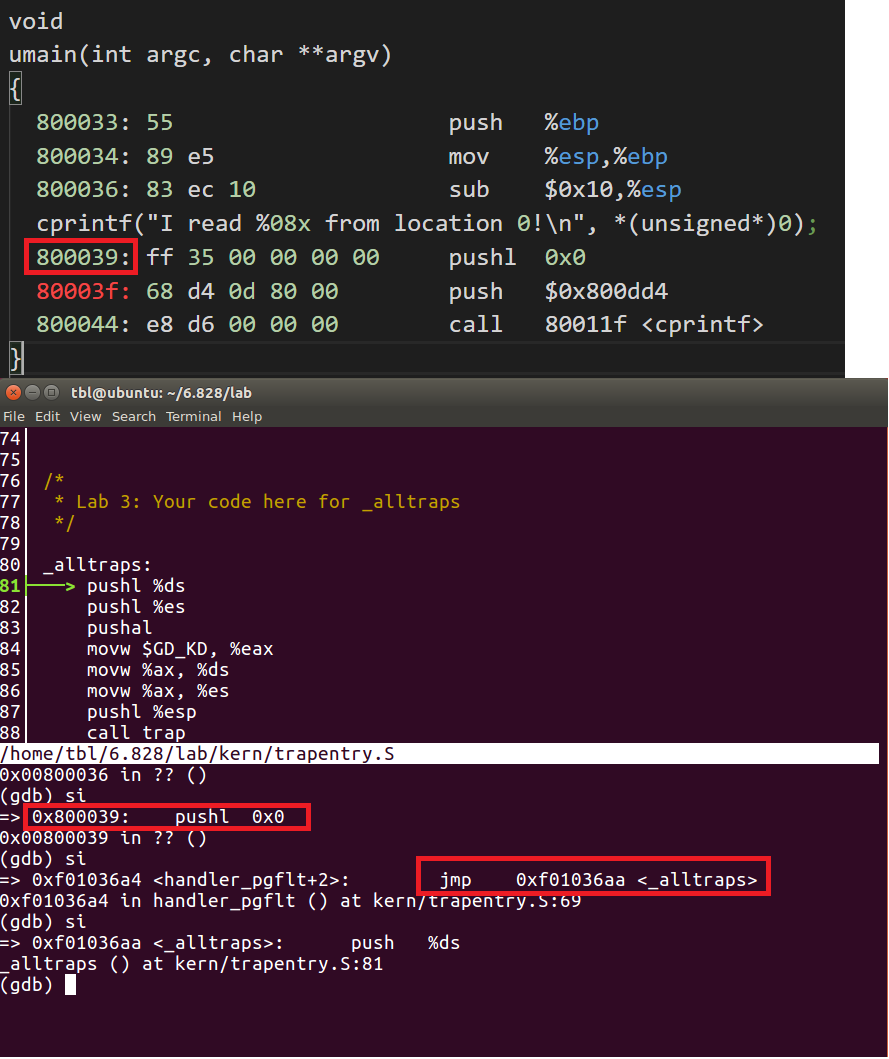
可以看到,在调用cprintf的第一个指令后就中断了,具体怎么触发的感觉不是很清楚,感觉应该是有一个地址检测的机制?(这里不是很懂)
exercise 5
修改trap_dispatch()函数,使得发生页错误异常的时候触发page_fault_handler()。
switch(tf->tf_trapno){
case T_PGFLT:
page_fault_handler(tf);
return ;
}
The Breakpoint Exception
这一个功能就是实现我们平时断点的功能,实现的原理也很简单,就是在断点的语句前面加上int $3。
JOS中进入后就是进入monitor shell。
exercise 6
修改trap_dispatch,使断点异常发生时能够调用kernel monitor。修改完成后重新make grade 应该能够通过breakpoint 测试。
switch(tf->tf_trapno){
case T_PGFLT:
page_fault_handler(tf);
return ;
case T_BRKPT:
monitor(tf);
return ;
}
Q3: 在breakpoint.c的的测试中,这个测试的例程要么会产生一个断点异常,要么会产生一个general protection fault的异常,产生哪种异常取决于如何初始化中断向量表IDT的。为什么?
SETGATE(idt[T_BRKPT], 0, GD_KT, handler_brkpt, 3);//产生Break point的中断
SETGATE(idt[T_BRKPT], 0, GD_KT, handler_brkpt, 0);//产生General Protection
DPL 字段为段描述符优先级,如果当前程序为用户态但是尝试调用内核态的指令的时候就会触发general protection exception。只有当前程序的优先级小于或等于段描述符优先级才能触发正确的breakpoint exception。
Q4:你认为为什么要中断的机制,特别是考虑到user/softint测试例程中的行为?
这样使得用户态不能随意的访问内核的代码和内存,使得内核不受用户程序的破坏。
System calls
system call这一部分据说用户态能够从用户态陷入到内核态进行资源的调用。
JOS中,我们特别使用int $0x30进行调用,
syscall函数输入: syscall number->%eax, 其余函数的变量放到 %edx, %ecx, %ebx, %edi, and %esi,最多支持五个变量。
并且最终的返回值保存到%eax中。
exercise 7
通过编辑kern/trapentry.S 以及kern/trap.c 的trap_init(),给T_SYSCALL 添加一个中断向量处理函数。同时trap_dispatch 也需要被修改,通过调用syscall 的方法来处理系统调用。最后,需要在kern/syscall.c 中首先实现syscall 函数。如果系统调用号不合法,需要syscall 返回-E_INVAL。
通过make run-hello 运行user/hello,qemu 应该打印处hello, world,并触发一个page fault。并且make grade 应该能够通过testbss 测试。
// kern/trapentry.S
TRAPHANDLER_NOEC(handler_syscall, T_SYSCALL);
// trap_init函数中添加handler_syscall
SETGATE(idt[T_SYSCALL], 0, GD_KT, t_syscall, 3);
// kern/trap.c
case T_SYSCALL:
tf->tf_regs.reg_eax = syscall(
tf->tf_regs.reg_eax,
tf->tf_regs.reg_edx,
tf->tf_regs.reg_ecx,
tf->tf_regs.reg_ebx,
tf->tf_regs.reg_edi,
tf->tf_regs.reg_esi);
return ;
// 然后在kern/syscall.c 中完成对于syscall 的实现,从而完成对于整个int 指令的调用:
// Dispatches to the correct kernel function, passing the arguments.
int32_t
syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
{
// Call the function corresponding to the 'syscallno' parameter.
// Return any appropriate return value.
// LAB 3: Your code here.
switch (syscallno) {
case SYS_cputs:
sys_cputs((char *)a1, a2);
return 0;
case SYS_cgetc:
return sys_cgetc();
case SYS_getenvid:
return sys_getenvid();
case SYS_env_destroy:
return sys_env_destroy(a1);
default:
return -E_INVAL;
}
panic("syscall not implemented");
}
User-mode startup
运行相应的用户态程序。
如果在/kern/init.c中加入了ENV_CREATE(user_hello, ENV_TYPE_USER);,就能执行相应的语句,确保sys_getenvid()执行的正确性(这一步会进行中断调用)。
从内核启动用户态程序的过程:
根据前面的铺垫,首先是分配相应的进程空间,然后进行虚拟内存的映射,加载相关的二进制代码。当相关的内核状态初始化完成之后,就运行/lib/entry.S中的程序,这个过程运行在用户态,然后通过libmain.c通过调用umain()函数调用相关用户态程序。
exercise 8
Add the required code to the user library, then boot your kernel. You should see
user/helloprint "hello, world" and then print "i am environment 00001000".user/hellothen attempts to "exit" by callingsys_env_destroy()(seelib/libmain.candlib/exit.c). Since the kernel currently only supports one user environment, it should report that it has destroyed the only environment and then drop into the kernel monitor. You should be able to get make grade to succeed on thehellotest.
// /lib/libmain.c
thisenv = envs + ENVX(sys_getenvid());
Page faults and memory protection
内存保护是一件非常重要的事情,使得一个程序的bugs不会干扰其他程序的内容或者正常的运行。
一般内存保护机制是硬件的支持,并且陷入到内核态。如果程序能够被修复,那么程序将会继续正常的执行,若无法修复,程序就无法正常的继续执行。
可修复的错误的例子:一开始内核给程序分配了一个函数栈,当调用的栈大小超过了指定大小时,报错陷入内核,内核会继续给该程序分配相应大小的内核栈,使得程序中断之后还能够继续执行。这一部分功能的实现在lab4中会进行具体的实现。
从用户态进行syscall时,陷入到内核态仍然需要对传入的参数进行解引用,相当于在用户态进行读写。这样做其实有两个问题:
- kernel page fault 和 user environment page fault两者的严重程度是不同的,在syscall调用造成的用户态page fault系统内核要能够正确的区分。
- 内核和用户态的权限往往是有很大的不同的,系统内核要能够进行区分。
因此,当在内核态遇到指针解引用时,要严格的对用户态传入的指针进行检查,如果是用户态的指针出现错误,那么就应该报出page fault,如果是内核中的指针出现错误,那么就应该panic and terminate,使得整个系统宕掉,因为这个是内核的错误,不能允许错误的出现。
exercise 9
修改
kern/trap.c,如果在kernel mode发生 page fault, 那么就panic。hint: 使用tf_cs来检测是在用户态还是在内核态
阅读
/kern/pmap.c中的user_mem_assert,并且完成函数的功能的实现。对system call的函数变量进行检查。
运行
user/buggyhello能够正确的触发user_mem_check。最后,在
/kern/kdebug.c中更改debuginfo_eip, 该函数调用user_mem_check。之后运行user/breakpoint使得,陷入到monitor shell之后能够运行backtrace查看之前栈的情况,能够看到是/lib/libmain.c的调用信息。并且在traceback的时候会产生一个page fault。你不需要修复它,但是你要能够说明为什么会产生这样的错误。
首先判断错误是来自用户态还是来自内核态的:
// Handle kernel-mode page faults.
if (tf->tf_cs == GD_KT)
panic("page_fault_handler: kernel page fault");
// LAB 3: Your code here.
user_mem_assert函数调用的是user_mem_check,它的作用是检查[va, va+len)这段用户态内存是否拥有perm|PTE_P权限。
int
user_mem_check(struct Env *env, const void *va, size_t len, int perm)
{
// LAB 3: Your code here.
uint32_t start = (uint32_t)ROUNDDOWN(va, PGSIZE);
uint32_t end = (uint32_t)ROUNDUP(va + len, PGSIZE);
pte_t *page;
for (; start < end; start += PGSIZE) {
page = pgdir_walk(env->env_pgdir, (void *)start, 0);
if (!page || start > ULIM || ((uint32_t)(*page) & perm) != perm ) {
if (start <= (uint32_t)va)
user_mem_check_addr = (uintptr_t)va;
else
user_mem_check_addr = (uintptr_t)start;
return -E_FAULT;
}
}
return 0;
}
我们看到当运行用户态程序buggyhello.c中的程序的时候,需要输出相应的错误信息,发现调用的是sys_cputs(),因此该系统调用下进行相应的内存地址的判断:
static void
sys_cputs(const char *s, size_t len)
{
// Check that the user has permission to read memory [s, s+len).
// Destroy the environment if not.
// LAB 3: Your code here.
user_mem_assert(curenv, s, len, 0);
// Print the string supplied by the user.
cprintf("%.*s", len, s);
}
最后修改kern/kdegbug.c 中的debuginfo_eip。添加如下代码:
// Make sure the STABS and string table memory is valid.
// LAB 3: Your code here.
if(user_mem_check(curenv, usd, sizeof(struct UserStabData), PTE_U))
return -1;
在运行/user/breakpoint.c测试例程后,产生系统中断而进入monitor模式,此刻使用backtrace会打印一些错误的信息,但是这个时候还是会产生新的page fault,为什么呢?

可以看到回溯的时候,用户态的栈指针越界了,从而会产生page fault的错误。
* USTACKTOP ---> +------------------------------+ 0xeebfe000
exercise 10
上面对用户传入内核指针地址的功能对恶意程序也同样适用,在运行
user/evilhello.c中该程序尝试着打印内核的入口地址,也能正确的报错,并且内核不会panic。
本部分不需要进行任何的代码的实现,仅仅是测试样例的补充。
